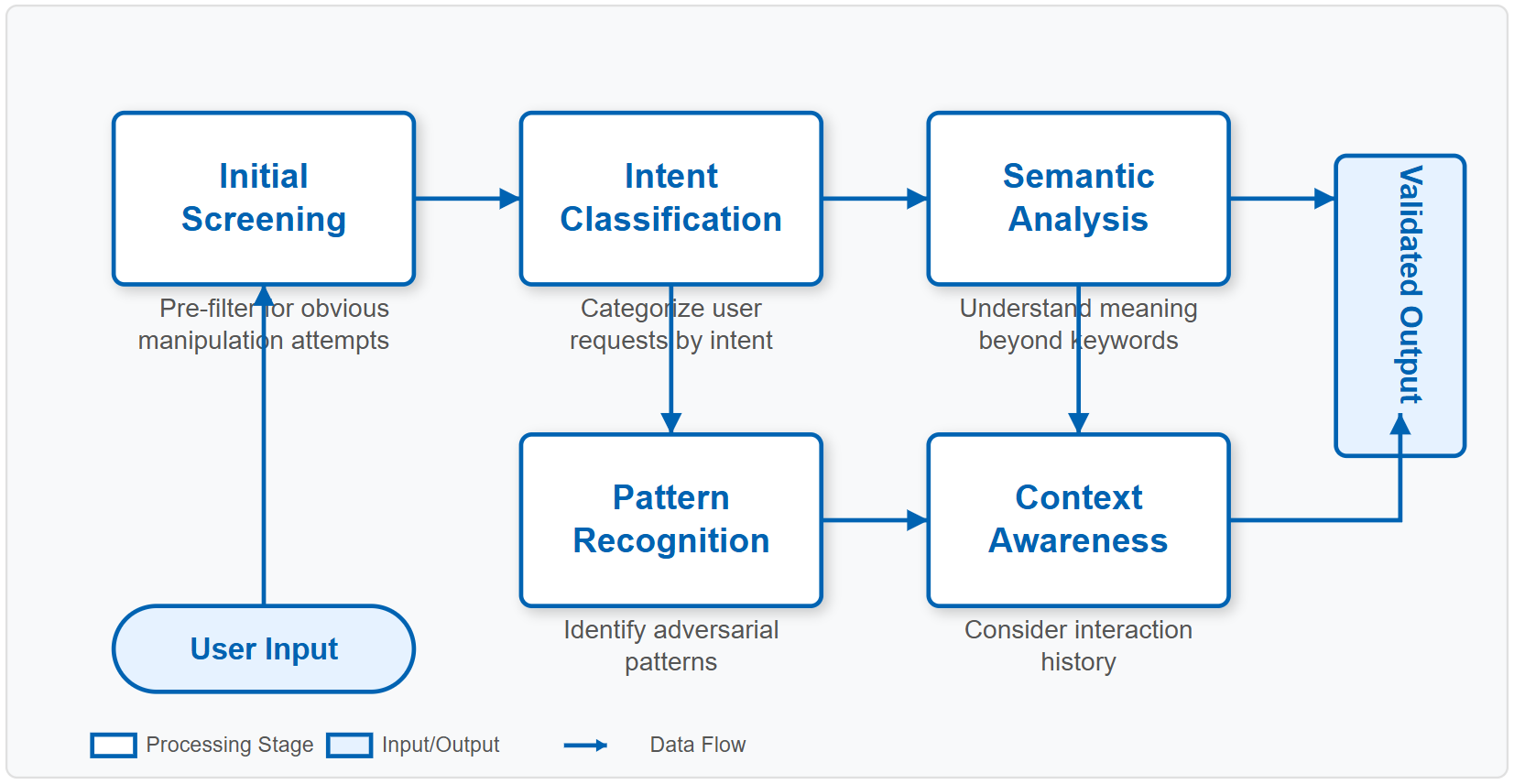
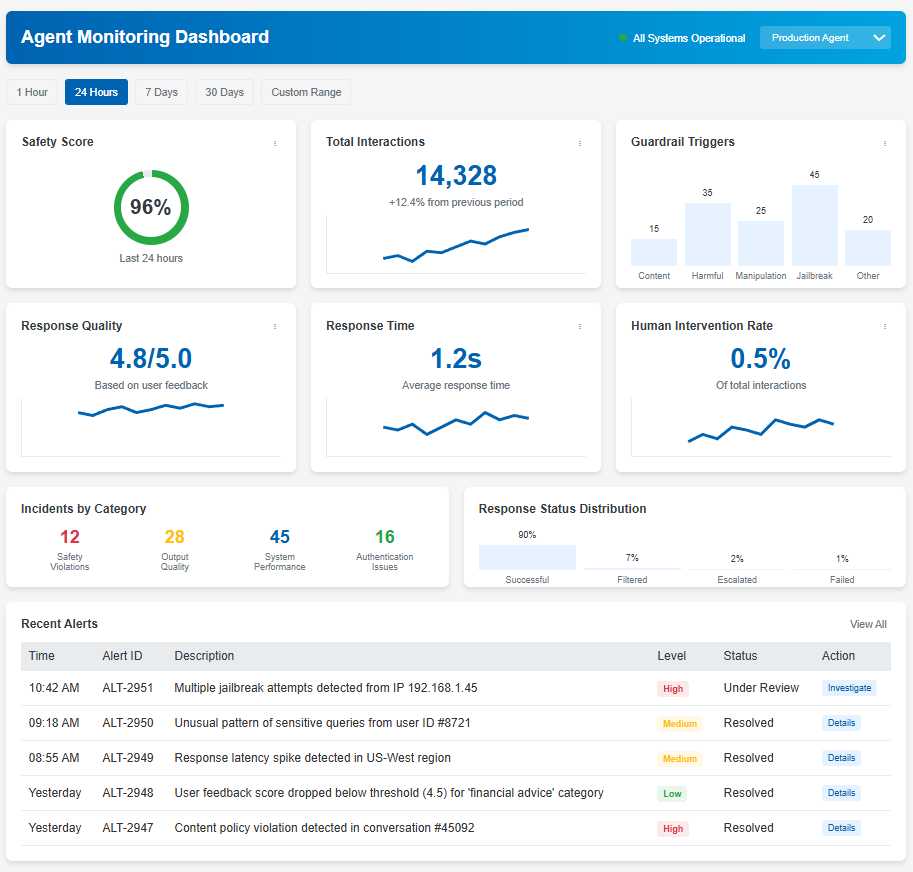
1. Introduction to Advanced Guardrails
As AI agents become more powerful, implementing robust guardrails becomes increasingly critical for
safe, reliable, and trustworthy operation.
Why Advanced Guardrails Matter
- Basic guardrails are necessary but insufficient for complex agent systems
- Advanced agents require multi-layered protection mechanisms
- Guardrails protect both users and your organization from unintended consequences
- Different use cases and domains require specialized guardrail strategies
Key Objectives
- Ensure agent behavior aligns with intended use cases
- Prevent harmful, illegal, or unethical actions
- Maintain data privacy and information security
- Create graceful failure modes when unexpected situations arise
- Establish monitoring and intervention protocols
"Advanced guardrails don't just prevent negative outcomes, they actively guide your agent toward more
helpful, accurate, and reliable behavior in complex real-world scenarios."
 Lonely Octopus
Lonely Octopus